# import modulesimportosimportnumpyasnpimportpandasaspdimportxarrayasxrfromtqdmimporttqdmimportmatplotlib.pyplotaspltimportcsvimportcartopy.crsasccrsimportcartopy.featureascfeature# functionsdefcheck_data_folder(folder):returnos.path.exists(folder)andos.path.isdir(folder)defgenerate_date_range(start_date,end_date):"""
Generate a list of dates from start_date to end_date.
"""returnpd.date_range(start=start_date,end=end_date,freq='D').strftime('%Y%m%d').tolist()defload_data(file_path):"""
Load data from a NetCDF file.
"""ifos.path.exists(file_path):returnxr.open_dataset(file_path)else:raiseFileNotFoundError(f'File not found: {file_path}')# main program## check data folderdata_folder=f'..\\..\\..\\surface_air_temperature\\data2024'ifcheck_data_folder(data_folder):print(f'Data folder found: {data_folder}')else:raiseFileNotFoundError(f'Data folder not found: {data_folder}')## load datastart_date='2024-01-01'end_date='2024-12-31'date_list=generate_date_range(start_date,end_date)## get location and shapepath=os.path.join(data_folder,f'M2T1NXFLX.5.12.4%3AMERRA2_400.tavg1_2d_flx_Nx.{date_list[0]}.nc4.dap.nc4')nc4_data=load_data(path)lat=nc4_data['lat'].valueslon=nc4_data['lon'].valuesshape=nc4_data['TLML'].shapetotal_locations=shape[1]*shape[2]## combine datasample_path=os.path.join(data_folder,f'M2T1NXFLX.5.12.4%3AMERRA2_400.tavg1_2d_flx_Nx.{date_list[0]}.nc4.dap.nc4')sample_data=load_data(sample_path)shape_per_file=sample_data['TLML'].shape# e.g. (24, 361, 576)time_per_file=len(sample_data['time'])total_samples=len(date_list)combined=np.empty((total_samples*shape_per_file[0],*shape_per_file[1:]),dtype=np.float32)time_list=np.empty(total_samples*time_per_file,dtype=sample_data['time'].dtype)fori,dateinenumerate(tqdm(date_list,desc="Combining")):path=os.path.join(data_folder,f'M2T1NXFLX.5.12.4%3AMERRA2_400.tavg1_2d_flx_Nx.{date}.nc4.dap.nc4')nc4_data=load_data(path)start=i*shape_per_file[0]end=(i+1)*shape_per_file[0]combined[start:end]=nc4_data['TLML'].valuestime_list[start:end]=nc4_data['time'].valuesprint(f'Combined data shape: {combined.shape}')## reshape datalocations=np.stack(np.meshgrid(lon,lat),axis=-1).reshape(-1,2)reshaped_data=combined.reshape(combined.shape[0],-1)pd.DataFrame(reshaped_data)# 2d data with time as rows and locations as columnsreshaped_df=pd.DataFrame(reshaped_data,columns=[f"({lon}, {lat})"forlon,latinlocations],index=list(time_list))time_num=len(time_list)locations_num=len(locations)## reshape data to (24, day, location) (24 hours)reshaped_df.index=pd.to_datetime(reshaped_df.index)groups=reshaped_df.groupby(reshaped_df.index.time)stacked=np.stack([group.to_numpy()fortime,groupinsorted(groups)])print(stacked)time_order=sorted(groups.groups.keys())print(time_order)## train setnp.random.seed(123)valid_mask=(locations[:,0]>=73)&(locations[:,0]<=104)& \
(locations[:,1]>=36)&(locations[:,1]<=54)# 緯度valid_indices=np.where(valid_mask)[0]day_num_train=250known_locations_num=valid_indices.shape[0]-350# 81.1%unknown_locations_num=350# 18.9%locations_num=known_locations_num+unknown_locations_numlocations_index=np.random.choice(valid_indices,size=locations_num,replace=False)known_locations_index=locations_index[:known_locations_num]unknown_locations_index=locations_index[known_locations_num:(known_locations_num+unknown_locations_num)]known_locations_index.sort()unknown_locations_index.sort()known_locations_choose=locations[known_locations_index,:]unknown_locations_choose=locations[unknown_locations_index,:]stacked_train=stacked[:,:day_num_train,known_locations_index]future_days=10known_real_data=stacked[:,:day_num_train+future_days,known_locations_index]unknown_real_data=stacked[:,:day_num_train+future_days,unknown_locations_index]print(f'Load data complete!')
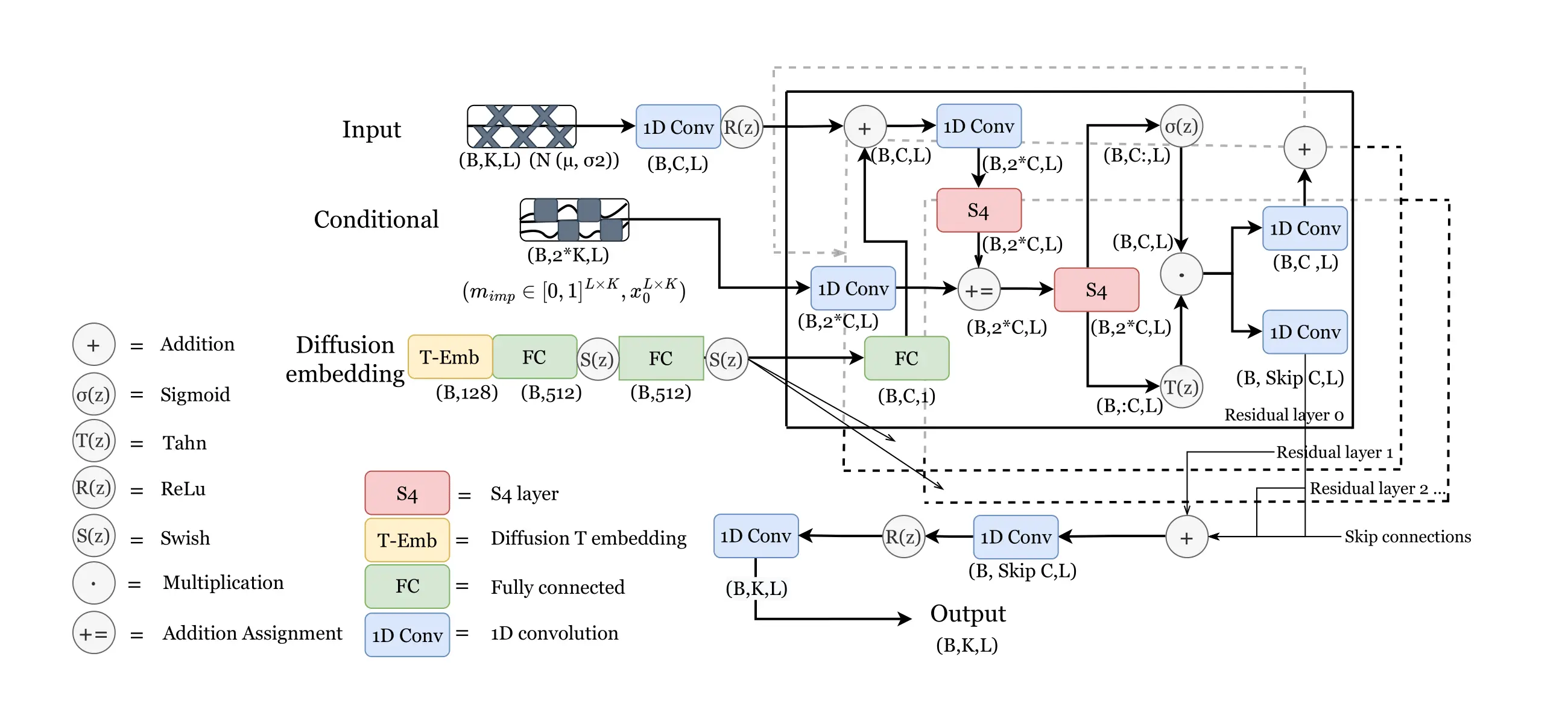
SSSD(Structured State Space Diffusion)是一種結合了條件擴散模型(conditional diffusion model)與結構化狀態空間序列模型(structured state spaces sequence model, S4)的生成式時間序列補值與預測方法。 S4 層能有效捕捉長期依賴性,而 diffusion 機制則提升補值的靈活度與表現力,對於缺值補全與未來趨勢模擬皆擁有優異表現。
wavenet:# WaveNet model parametersinput_channels:24# Number of input channelsoutput_channels:24# Number of output channelsresidual_layers:32# Number of residual layersresidual_channels:64# Number of channels in residual blocksskip_channels:64# Number of channels in skip connections# Diffusion step embedding dimensionsdiffusion_step_embed_dim_input:128# Input dimensiondiffusion_step_embed_dim_hidden:512# Middle dimensiondiffusion_step_embed_dim_output:512# Output dimension# Structured State Spaces sequence model (S4) configurationss4_max_sequence_length:250# Maximum sequence lengths4_state_dim:64# State dimensions4_dropout:0.0# Dropout rates4_bidirectional:true# Whether to use bidirectional layerss4_use_layer_norm:true# Whether to use layer normalizationdiffusion:# Diffusion model parametersT:200# Number of diffusion stepsbeta_0:0.0001# Initial beta valuebeta_T:0.02# Final beta value
# Training configurationbatch_size:300# Batch sizeoutput_directory:"./results/surface air temperature/control"# Output directory for checkpoints and logsckpt_iter:"max"# Checkpoint mode (max or min)iters_per_ckpt:100# Checkpoint frequency (number of epochs)iters_per_logging:100# Log frequency (number of iterations)n_iters:3800# Maximum number of iterationslearning_rate:0.0005# Learning rate# Additional training settingsonly_generate_missing:true# Generate missing values onlyuse_model:2# Model to use for trainingmasking:"forecast"# Masking strategy for missing valuesmissing_k:10# Number of missing values# Data pathsdata:train_path:"./datasets/surface air temperature/train/train.npy"# Path to training data
# Inference configurationbatch_size:300# Batch size for inferenceoutput_directory:"./results/surface air temperature/inference/control"# Output directory for inference resultsckpt_path:"./results/surface air temperature/control"# Path to checkpoint for inferencetrials:1# Replications# Additional training settingsonly_generate_missing:true# Generate missing values onlyuse_model:2# Model to use for trainingmasking:"forecast"# Masking strategy for missing valuesmissing_k:10# Number of missing values# Data pathsdata:test_path:"./datasets/surface air temperature/test/test.npy"# Path to test data
fromdarts.modelsimportTSMixerModelfromdartsimportTimeSeriesfromdatetimeimportdatetimefromtqdmimporttqdmreal_data=known_real_datalocation_choose=known_locations_chooselocations_index=known_locations_indexinference=np.array([[[0.0]*real_data.shape[2]]*future_days]*real_data.shape[0])start_time=datetime.now()foriintqdm(range(real_data.shape[0])):train_set=real_data[i,:day_num_train,:]train_set=pd.DataFrame(train_set,index=pd.to_datetime(date_list[:day_num_train]),columns=[f"loc_{i}"foriinrange(known_locations_num)])train_set=TimeSeries.from_dataframe(train_set)test_set=real_data[i,day_num_train:,:]test_set=pd.DataFrame(test_set,index=pd.to_datetime(date_list[day_num_train:day_num_train+future_days]),columns=[f"loc_{i}"foriinrange(known_locations_num)])test_set=TimeSeries.from_dataframe(test_set)model=TSMixerModel(input_chunk_length=30,output_chunk_length=10,n_epochs=3800,dropout=0.0005,use_reversible_instance_norm=True,random_state=42,pl_trainer_kwargs={"accelerator":"gpu"})model.fit(train_set)forecast=model.predict(future_days)inference[i]=forecast.values()print(f'Inference complete! Time taken: {datetime.now()-start_time}')
fromdarts.modelsimportRegressionEnsembleModel,NaiveSeasonal,LinearRegressionModel,NaiveDriftfromdartsimportTimeSeriesfromdatetimeimportdatetimefromtqdmimporttqdmreal_data=known_real_datalocation_choose=known_locations_chooselocations_index=known_locations_indexinference=np.array([[[0.0]*real_data.shape[2]]*future_days]*real_data.shape[0])start_time=datetime.now()foriintqdm(range(real_data.shape[0])):train_set=real_data[i,:day_num_train,:]train_set=pd.DataFrame(train_set,index=pd.to_datetime(date_list[:day_num_train]),columns=[f"loc_{i}"foriinrange(known_locations_num)])train_set=TimeSeries.from_dataframe(train_set)test_set=real_data[i,day_num_train:,:]test_set=pd.DataFrame(test_set,index=pd.to_datetime(date_list[day_num_train:day_num_train+future_days]),columns=[f"loc_{i}"foriinrange(known_locations_num)])test_set=TimeSeries.from_dataframe(test_set)base_models=[NaiveSeasonal(K=7),LinearRegressionModel(lags=30),NaiveDrift()]model=RegressionEnsembleModel(forecasting_models=base_models,regression_train_n_points=30)model.fit(train_set)forecast=model.predict(n=future_days)inference[i]=forecast.values()print(f'Inference complete! Time taken: {datetime.now()-start_time}')
Global Modeling and Assimilation Office (GMAO)。(2015)。MERRA-2 tavg1_2d_flx_Nx: 2d,1-Hourly,Time-Averaged,Single-Level,Assimilation,Surface Flux Diagnostics (Version 5.12.4) [資料集]。Goddard Earth Sciences Data and Information Services Center (GES DISC)。參考自 https://doi.org/10.5067/7MCPBJ41Y0K6
Juan Lopez Alcaraz 、 Nils Strodthoff(2022)。Diffusion-based time series imputation and forecasting with structured state space models。Transactions on Machine Learning Research。參考自 https://openreview.net/forum?id=hHiIbk7ApW
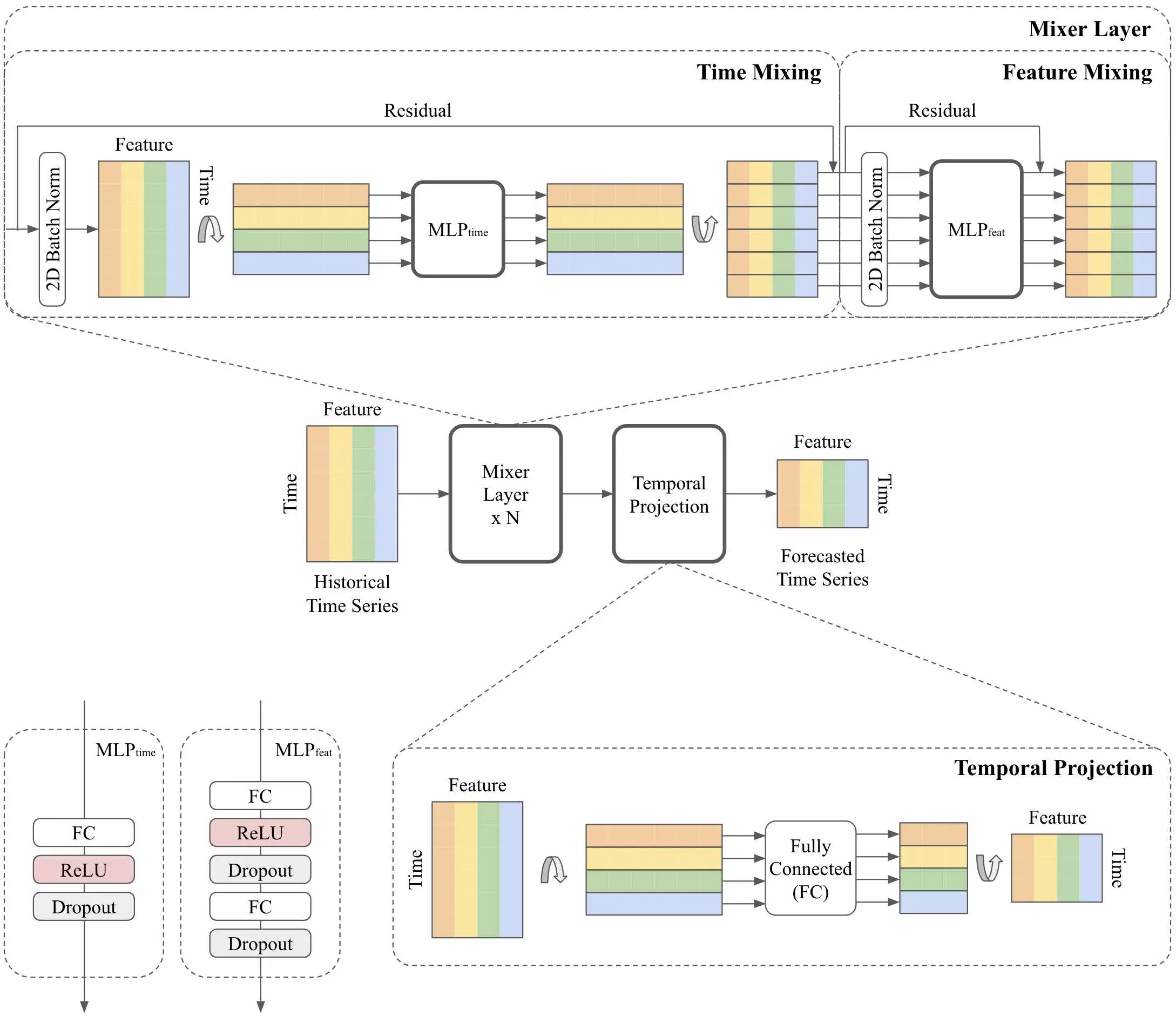
Si-An Chen, Chun-Liang Li, Nate Yoder, Sercan O. Arik and Tomas Pfister. (2023). TSMixer: An all-MLP architecture for time series forecasting. arXiv. 參考自 https://arxiv.org/abs/2303.06053