安斯庫姆四重奏
,這是一個我從未聽說過的詞,但卻與統計學與資料視覺化有著重要的影響。")
封面圖片是由 ChatGPT 所生成的安斯庫姆四重奏,提示詞為 “The digital design highlights the title ‘Anscombe’s Quartet’ in bold, white sans-serif letters, centered against a dynamic abstract backdrop. The image is split into four colorful quadrants, each showcasing unique textures and patterns—ranging from painterly hues and curved lines to scattered circles and dots.” 。
前言
今天在聽取報告時,偶然聽見一個名詞——安斯庫姆四重奏(Anscombe’s quartet),這是一個我從未聽說過的詞,但卻與統計學與資料視覺化有著重要的影響。
歷史
安斯庫姆四重奏是由英國統計學家弗蘭克·安斯庫姆(Francis Anscombe)於西元 1973 年建構出來的四組數據,而這四組數據擁有近乎相同的統計特性,但卻在圖形表現上有著天壤之別。
安斯庫姆四重奏
安斯庫姆四重奏的四組數據值如下,每一組都有 11 對 $x$ 和 $y$ 值:
| $x_1$ | $y_1$ | $x_2$ | $y_2$ | $x_3$ | $y_3$ | $x_4$ | $y_4$ | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 10.0 | 8.04 | 10.0 | 9.14 | 10.0 | 7.46 | 8.0 | 6.58 | |||
| 8.0 | 6.95 | 8.0 | 8.14 | 8.0 | 6.77 | 8.0 | 5.76 | |||
| 13.0 | 7.58 | 13.0 | 8.74 | 13.0 | 12.74 | 8.0 | 7.71 | |||
| 9.0 | 8.81 | 9.0 | 8.77 | 9.0 | 7.11 | 8.0 | 8.84 | |||
| 11.0 | 8.33 | 11.0 | 9.26 | 11.0 | 7.81 | 8.0 | 8.47 | |||
| 14.0 | 9.96 | 14.0 | 8.10 | 14.0 | 8.84 | 8.0 | 7.04 | |||
| 6.0 | 7.24 | 6.0 | 6.13 | 6.0 | 6.08 | 8.0 | 5.25 | |||
| 4.0 | 4.26 | 4.0 | 3.10 | 4.0 | 5.39 | 19.0 | 12.50 | |||
| 12.0 | 10.84 | 12.0 | 9.13 | 12.0 | 8.15 | 8.0 | 5.56 | |||
| 7.0 | 4.82 | 7.0 | 7.26 | 7.0 | 6.42 | 8.0 | 7.91 | |||
| 5.0 | 5.68 | 5.0 | 4.74 | 5.0 | 5.73 | 8.0 | 6.89 |
我們使用 R 語言將以上的數據集進行簡單的分析。
輸入資料
如下,我們將上述的數據集輸入 R 語言,同時寫為矩陣形式,方便簡化操作。
| |
| |
平均值、變異數與相關係數
接下來我們檢查這筆數據的的平均值、變異數與相關係數。
我們發現了一個有趣的事實,這些數據的平均值、變異數至少到小數點後第 2 位都相同。而每一組成對的數據間,如 $(x_1, y_1)$,它們各組的相關係數也同樣至少到小數點後第 2 位都相同。
| |
| |
線性迴歸
接下來我們對這四組數據進行迴歸分析,我們會發現這四組竟然都有相似的迴歸方程
$$ y = 3 + 0.5 x. $$
| |
| |
這個巧合實在是太不可思議。到這裡,如果沒有檢查其它的統計性質,或許我們會認為這四組數據其實大差不差。但其實,這四組數據卻擁有截然不同的圖形,這些統計性質的相似只是巧合。
散佈圖
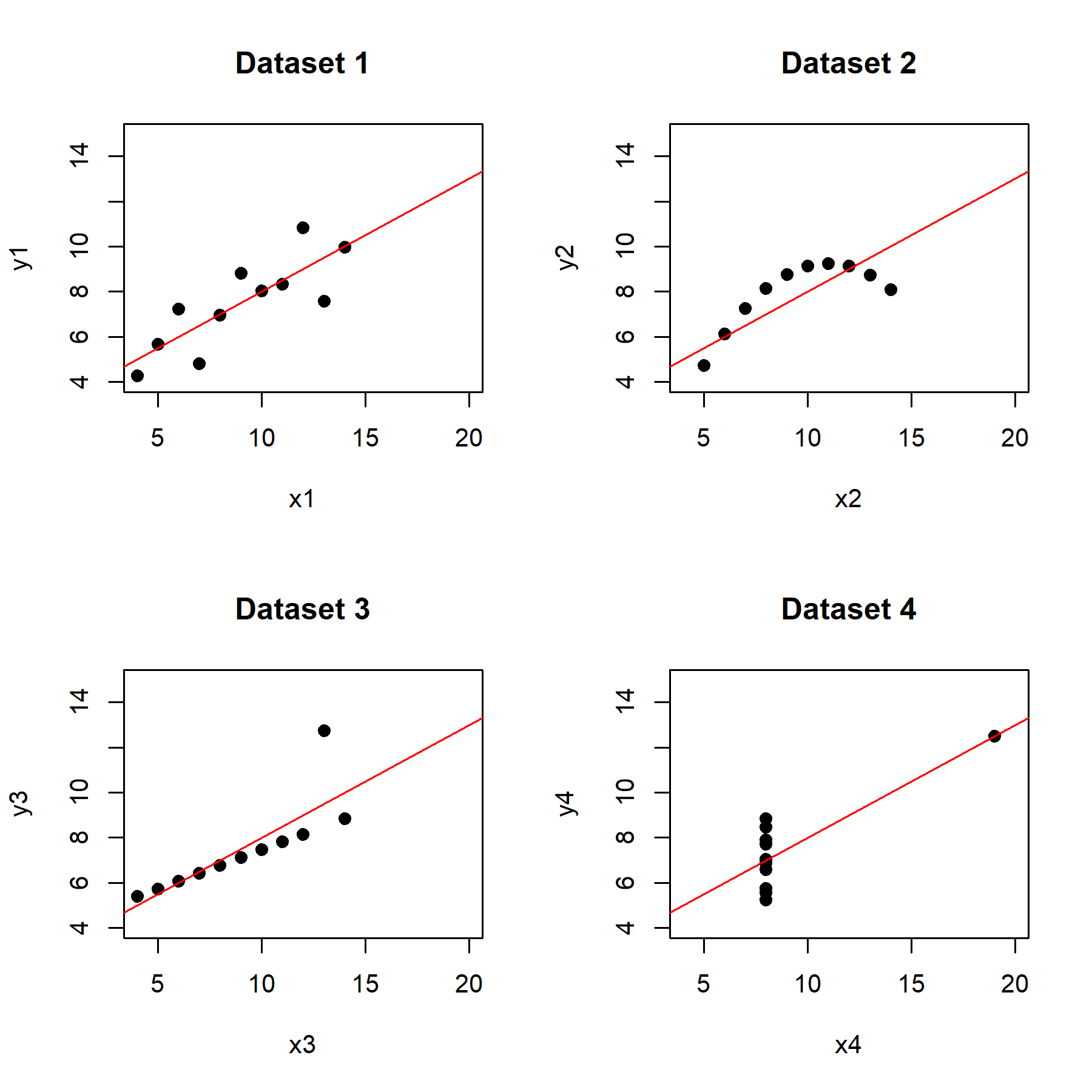
以下畫出這四組數據的散佈圖。我們可以從中發現第一組數據比較像是線性迴歸,兩種變量間存在著某種相關性;而第二組數據則可以很明顯地看到兩種變量之間存在著非線性關係;在第三與第四組數據中,可以很明顯地看到其各自存在一個離群值,使得這兩組數據的迴歸線受到影響。
| |
盒狀圖
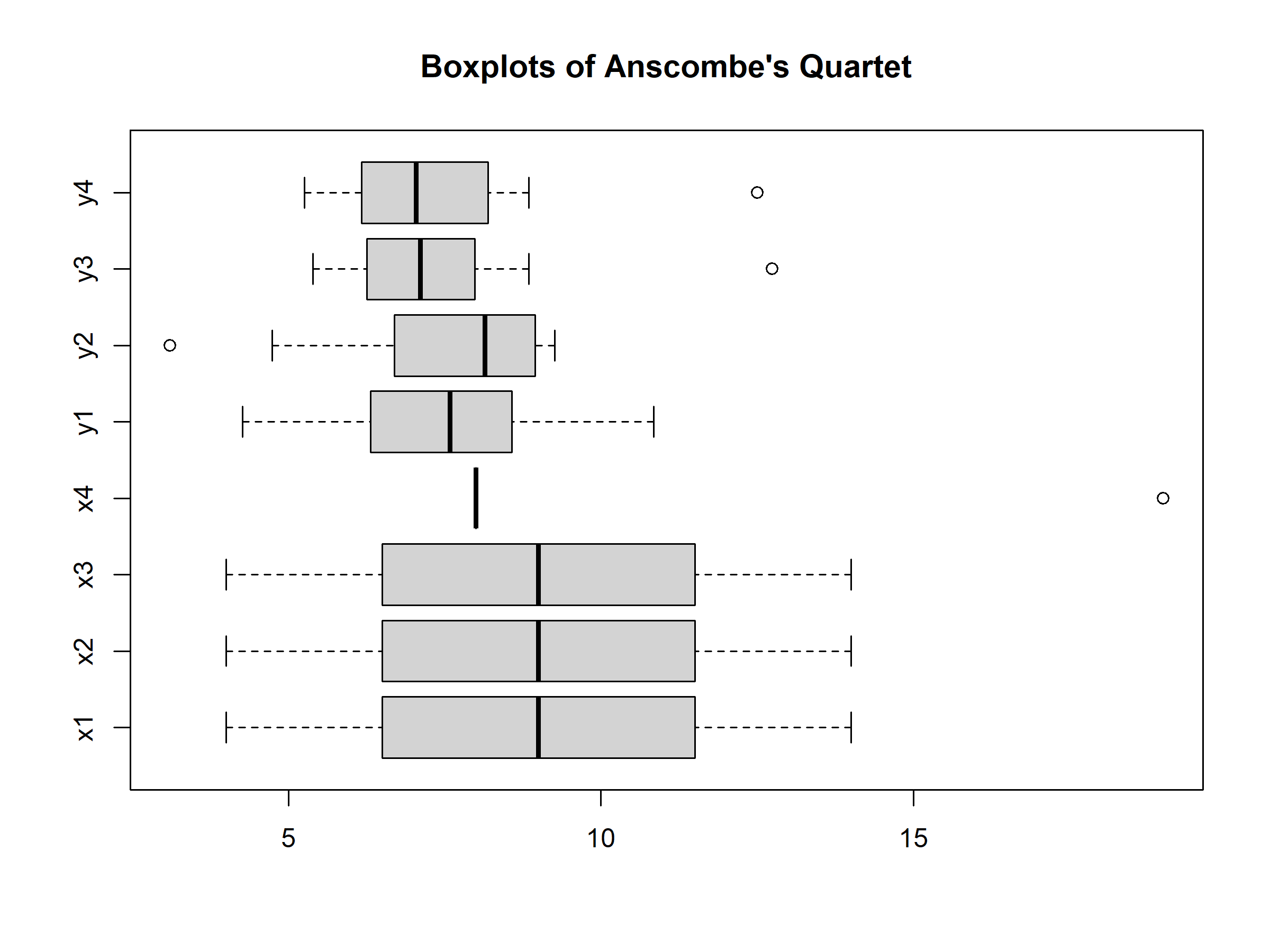
而從盒狀圖中,我們可以發現這四組數據的四分位數其實就有所不同。
| |
結語
安斯庫姆四重奏說明了進行資料分析時,我們不能夠只單純依靠計算所得到的資訊進行判讀,更應該藉由不同的資料觀,如資料的視覺化、不同的分析方式,更全面地檢視手中的資料。統計數字固然重要,但若不搭配不同的分析方式,可能會大大誤判資料的真實意義。
延伸學習
- 本文使用的 R Notebook html 檔案。
參考資料
- 安斯庫姆四重奏。(2021年9月23日)。維基百科,自由的百科全書。2025年6月3日參考自 https://zh.wikipedia.org/zh-tw/安斯库姆四重奏