資料集的定義
列為一筆觀測值(observation)並收集起來,我們就能粗略地得到一組由多筆數據結合在一起,可能是結構化(structured)或非結構化(unstructured)的數據集(dataset)。加以整理與篩選,把認為對自己有用的資訊(information)提出,並將無用的資訊剔除,就能得到一個可用於進行分析、訓練模型、或作為研究依據的資料集(dataset)。資料集可以包含數值、文字、圖片、音訊或影片等各種類型的資料,視其應用目的決定如何收集與整理。")
封面圖片是由 ChatGPT 生成的資料集定義圖片,提示詞為 “A flat-style digital illustration representing the concept of “dataset definition”, without any text. The scene features a computer monitor displaying a simple dataset table (columns and rows), surrounded by minimalistic icons such as a database, document, network, and a checkmark. These elements are connected with dotted lines, symbolizing relationships and data structure. The color palette is clean and modern, using tones like teal, blue, and white. The overall composition follows a 16:9 aspect ratio, with a professional and conceptual data visualization feel.” 。
前言
在這大數據時代,生活中處處充滿著不同的資訊,如果將每筆數據(data)列為一筆觀測值(observation)並收集起來,我們就能粗略地得到一組由多筆數據結合在一起,可能是結構化(structured)或非結構化(unstructured)的數據集(dataset)。加以整理與篩選,把認為對自己有用的資訊(information)提出,並將無用的資訊剔除,就能得到一個可用於進行分析、訓練模型、或作為研究依據的資料集(dataset)。資料集可以包含數值、文字、圖片、音訊或影片等各種類型的資料,視其應用目的決定如何收集與整理。
資料集的類型
資料集依照其結構與用途,大致可分為以下幾種:
結構化資料集(Structured Dataset)
以表格、列表等形式呈現的資料,每筆資料擁有固定的欄位(features)與統一的格式,方便儲存、查詢與分析。
例如:表格、資料庫的資料、以 .csv 儲存的檔案。
非結構化資料集(Unstructured Dataset)
不具有固定結構,無法直接對應為表格的資料。可能需要經過特定處理,才能使用的資料。
例如:圖片、影片、文字文件、小說。
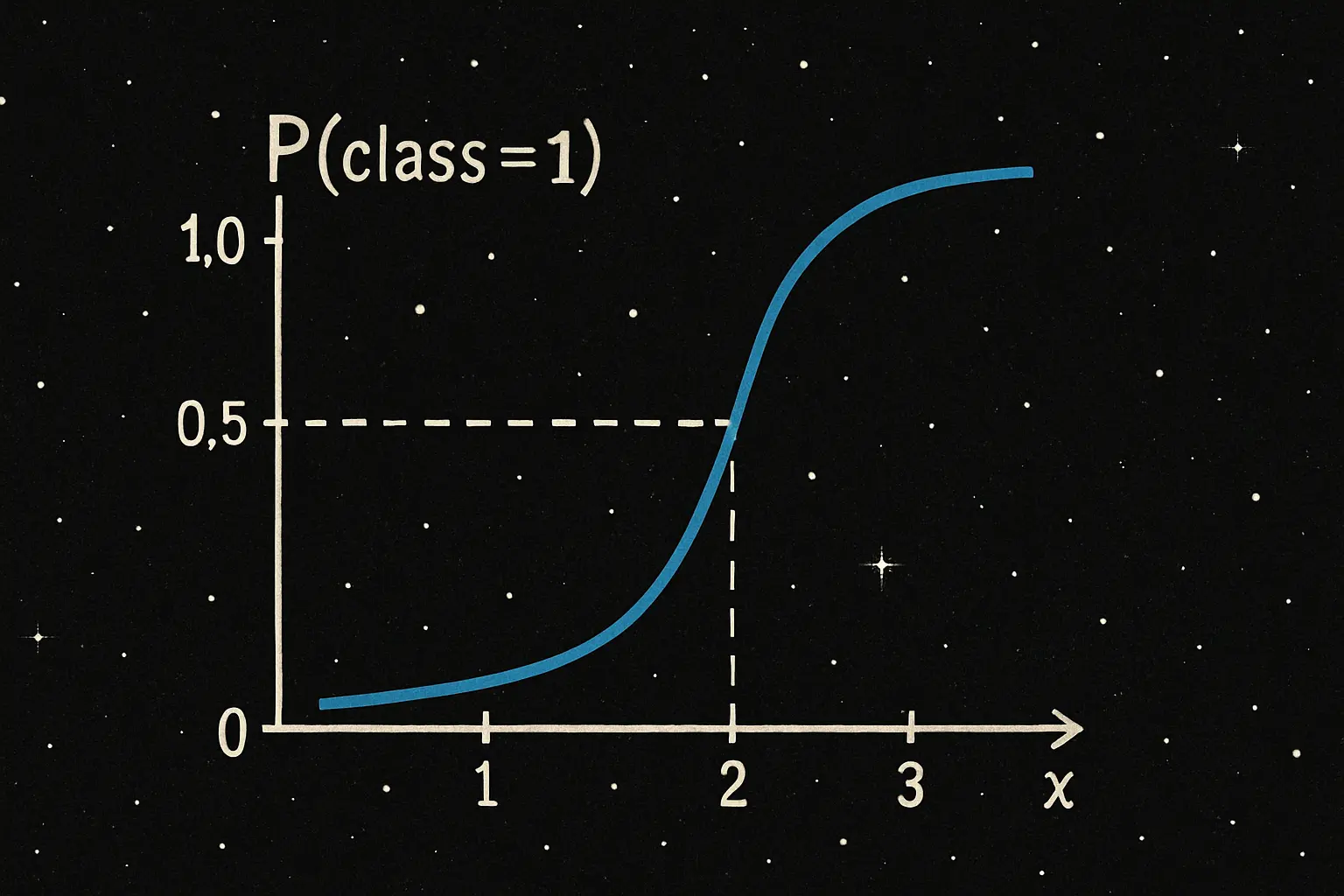
標註資料集(Labeled Dataset)
每筆資料都附有一個對應的標籤(label),且能幫助模型學習輸入與輸出之間的關係。常用於監督式學習(supervised learning)。
例如:手寫數字辨識資料集、鳶尾花資料集等具有標籤的資料集。
未標註資料集(Unlabeled Dataset)
資料沒有附加標籤,可能需要先進行資料分群、降維等分析的資料集。常用於非監督學習(unsupervised learning)。
例如:顧客購買紀錄、氣候資料、水溫資料等。
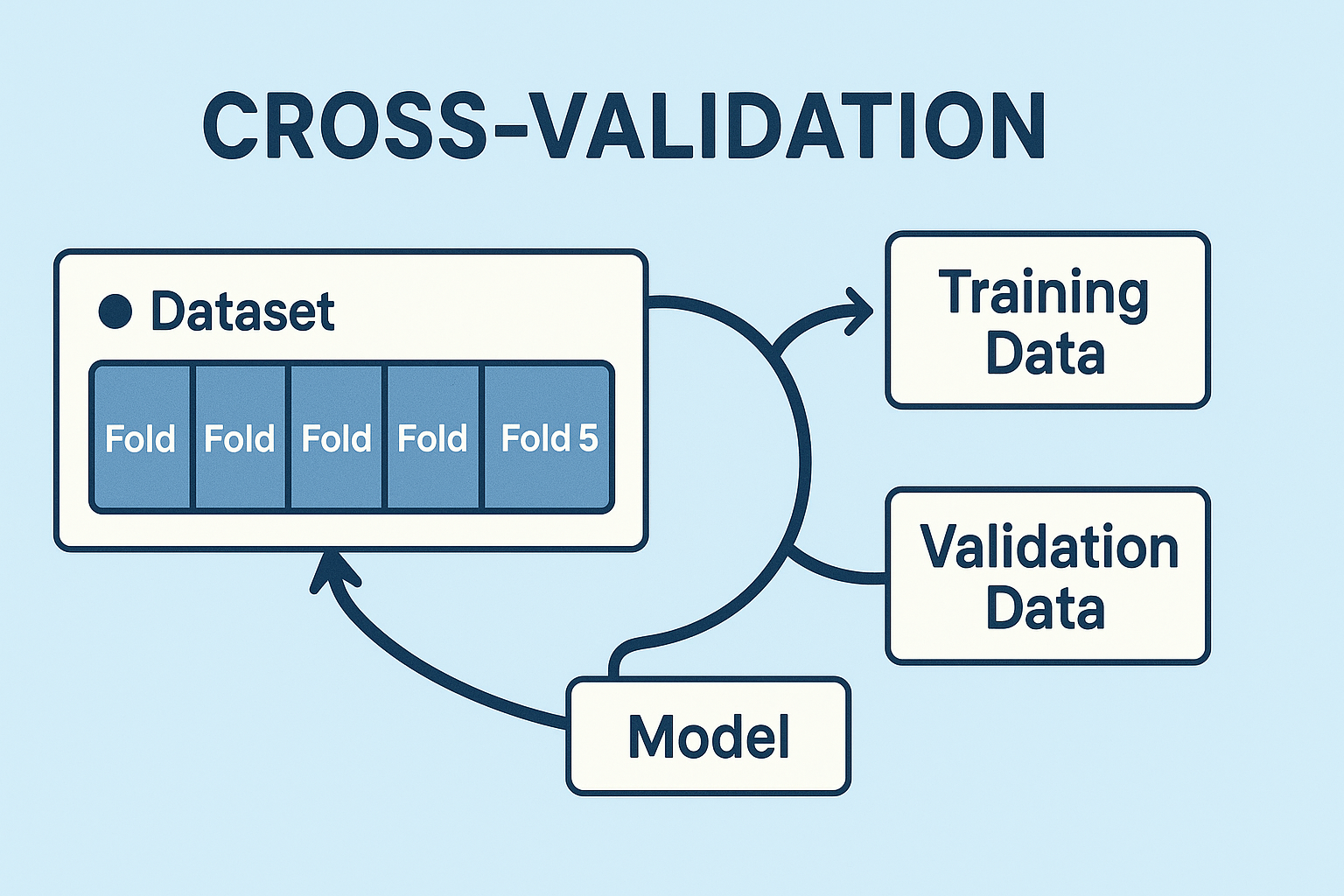
資料集的拆分
透過機器學習擬合資料集時,為了能測試模型對新資料的預測能力(即泛化能力),我們通常會將原始資料集進行拆分。由於可能無法即時取得全新的資料用於測試模型,因此我們會預先保留一部分資料作為測試用途。
最簡單的方法是將資料集拆分為兩份,分別為測試集(training set)與訓練集(test set)。但這種區分方式使模型無法根據測試結果及時做出調整,因此,我們會在訓練集中再拆分一份資料集作為驗證集(validation set),用於調整模型的超參數(hyperparameter)。
訓練集
訓練集是模型學習的基礎,用於讓模型擬合資料並找出輸入與輸出之間的關係,使模型能夠擬合並逼近資料集。
以直觀的例子來說,訓練集就像是學生在學校進行學習,透過反覆練習學習知識。
驗證集
驗證集是在模型訓練時,於每一個訓練週期的最後評估模型學習能力的資料集,並用於超參數調整。
驗證集就像學生在學校的平時小考,老師能夠依據學生的作答情況調整上課內容與教學策略。
同時,如果模型不需要調整超參數,則驗證集並不是必要的,可以省略。
測試集
測試集是整個模型訓練完,最後用來評估模型泛化能力的資料集,目的是測試模型在從未見過的新資料上的表現。與驗證集不同的是,測試集僅用於測試模型,不用於調整超參數。
舉例而言,測試集就是學校的期末考,用於評估、檢測學生整個學期的學習成果。
拆分比例
資料集的拆分比例並無硬性規定,常見的比例有
| 訓練集 | 驗證集 | 測試集 |
|---|---|---|
| 80% | 10% | 10% |
| 70% | 10% | 20% |
| 70% | 20% | 10% |
| 60% | 20% | 20% |
| 70% | 0% | 30% |
| 80% | 0% | 20% |
| 90% | 0% | 10% |
結語
資料集是大數據科學中重要的部分,無論是模型訓練、特徵抓取、研究分析等,都與資料集密不可分。學習並了解資料集的類型與拆分方式,讓我們更有效地管理與處理資料,提升模型的準確度與實用性。