機器學習初認識
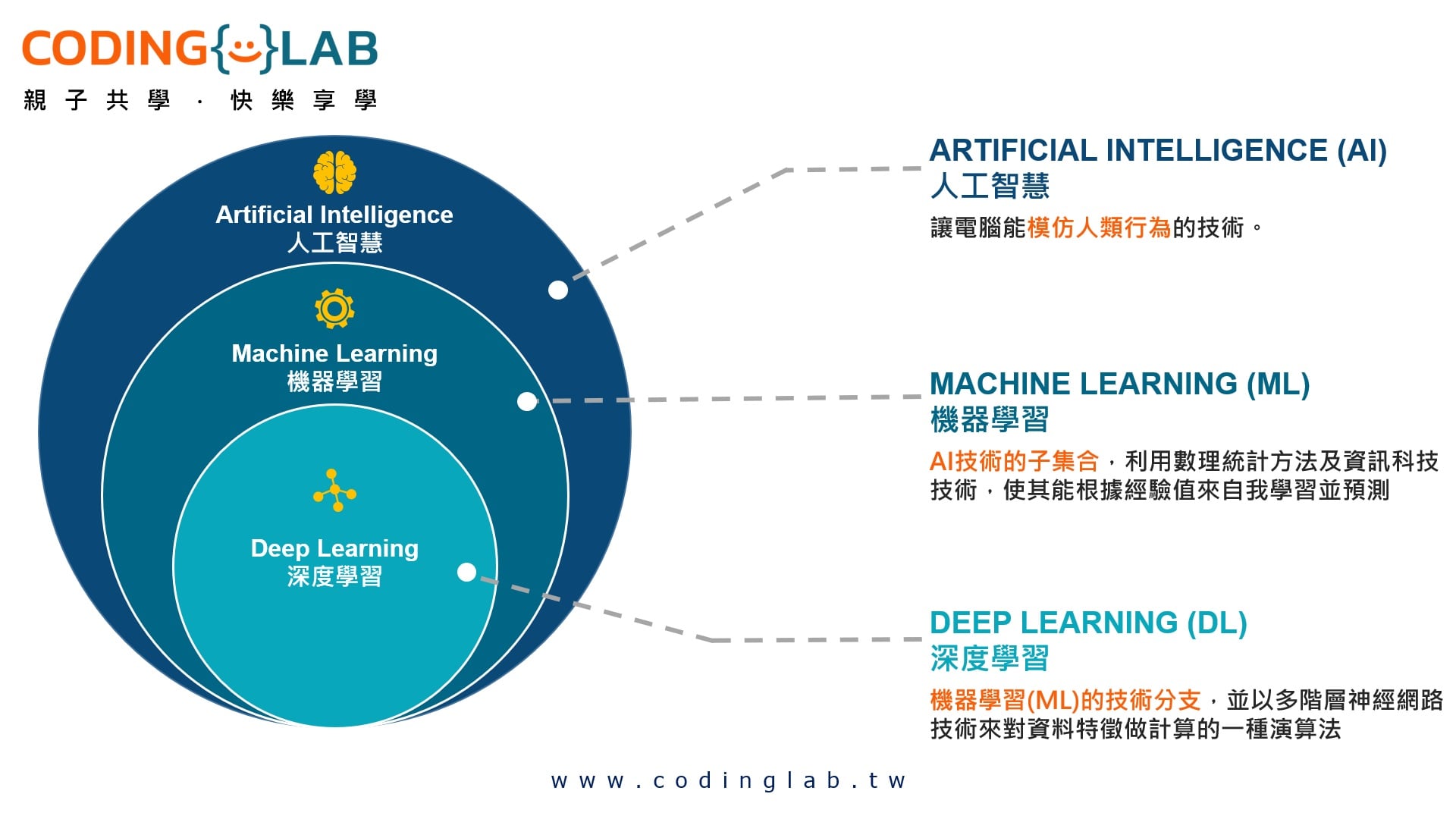
是人工智慧(artificial intelligence, AI)領域中的一個子領域,它使電腦能夠通過資料學習並進行預測或決策,而不需要人為一步一步計算。在傳統的資料分析與程式設計中,往往都需要要求開發者為每個分析的事件編寫具體規則。而機器學習依賴於資料,通過訓練模型自動識別規則或找到模式。隨著數位化時代的到來,每天都有大量的資訊、數據被產出、收集,無論這些資料集是否具有價值,又或是存在著不明顯且隱藏的資訊,我們都能嘗試使用機器學習找出這些資訊並加以利用。機器學習技術在各行各業中都有著重要應用,如金融、醫療、製造、以及自動駕駛等。")
封面圖片是由 ChatGPT 生成的認識機器學習圖片,提示詞為: “A hand-drawn 2D animation in the Studio Ghibli style showcasing an elderly, animated scientist with wild white hair and glasses, seated in a cozy, rustic classroom. In the background, a chalkboard labeled ‘MACHINE LEARNING’ is accompanied by a cute robot diagram, while elements like a vintage computer, natural light from a wooden-framed window, and earthy tones of the room’s structure enhance the warm ambiance of the setting.” 。
前言
機器學習(machine learning, ML)是人工智慧(artificial intelligence, AI)領域中的一個子領域,它使電腦能夠通過資料學習並進行預測或決策,而不需要人為一步一步計算。在傳統的資料分析與程式設計中,往往都需要要求開發者為每個分析的事件編寫具體規則。而機器學習依賴於資料,通過訓練模型自動識別規則或找到模式。隨著數位化時代的到來,每天都有大量的資訊、數據被產出、收集,無論這些資料集是否具有價值,又或是存在著不明顯且隱藏的資訊,我們都能嘗試使用機器學習找出這些資訊並加以利用。機器學習技術在各行各業中都有著重要應用,如金融、醫療、製造、以及自動駕駛等。
在本文中,我們將介紹機器學習的基本分類方法種類,包括監督式學習、非監督式學習、強化學習、半監督學習與主動學習。
監督式學習(Supervised Learning)
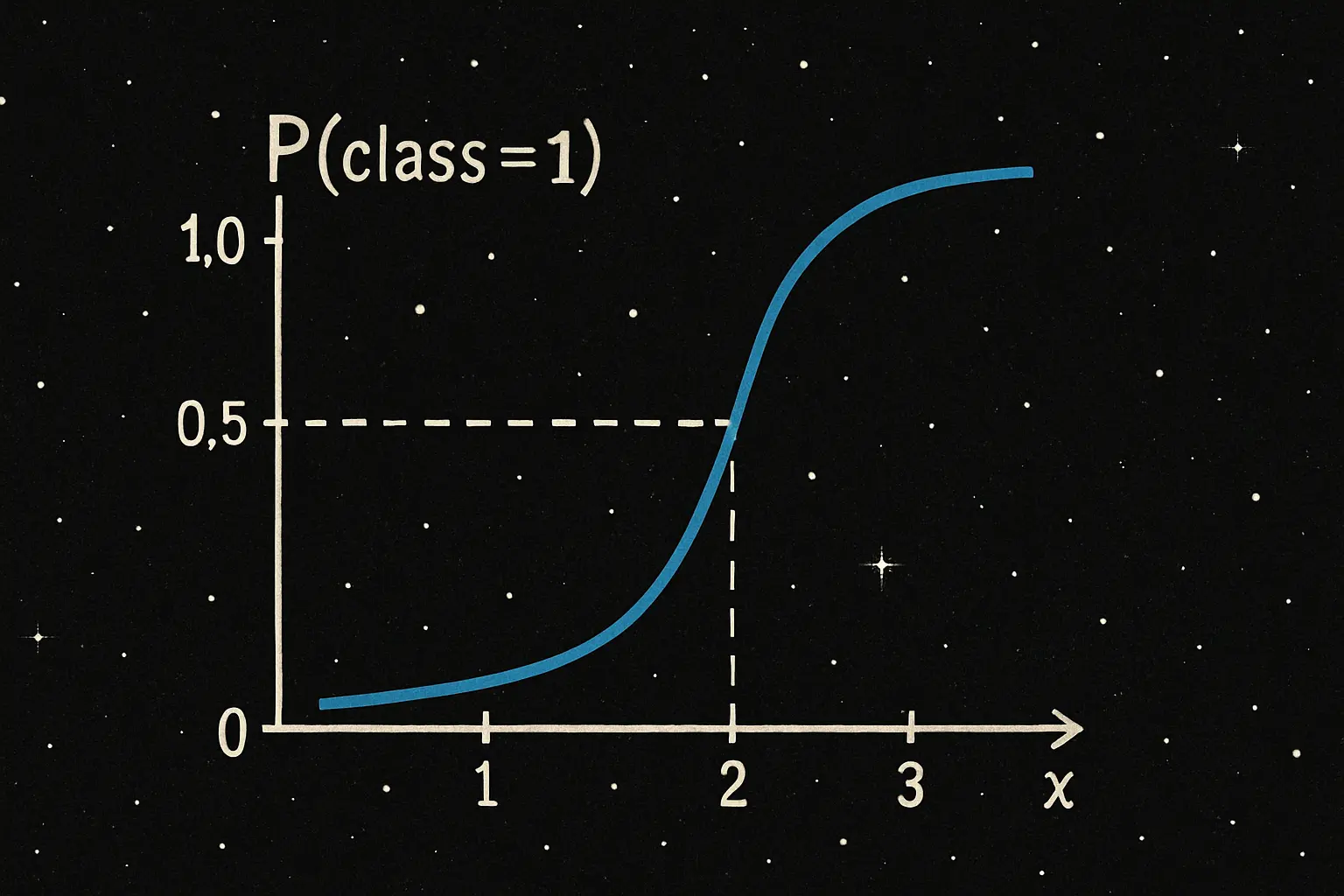
監督式學習是指從標注的資料中學習數據的趨勢並建立模型,同時對給定的輸入產生對應的預測輸出。通常標注資料集的過程都是由人工標示的,故稱作監督式學習。在標注的資料中,每個訓練資料都有對應的標籤(label),模型的目標是學習如何根據輸入的特徵(features)來預測標籤。監督式學習的本質是讓機器找出規律,學習如何將輸入映射到輸出。
監督式學習中所有可能的輸入與輸出的集合分別稱為輸入空間(input space)與輸出空間(output space)。輸入與輸出空間可以是任意的元素集合,甚至是整個歐幾里得空間(Euclidean space),但通常輸出空間會遠小於輸入空間。
$$ \text{輸出空間} \quad << \quad \text{輸入空間}. $$
流程
$$ [輸入數據(含標籤)] \rightarrow [模型訓練] \rightarrow [預測輸出] \rightarrow [誤差計算] \rightarrow [模型調整] \rightarrow [最終預測] $$
應用
監督式學習在分類和迴歸問題中廣泛應用。例如,在電子郵件分類中,模型學習如何將電子郵件分類為「垃圾郵件」或「非垃圾郵件」,又如在醫學領域,模型根據病人的檢查數據來預測是否患有某種疾病。
優缺點
優點:
- 可以通過清楚的目標標籤來進行訓練,準確度較高。
缺點:
- 需要大量標注資料,且訓練資料質量直接影響結果。
非監督式學習(Unsupervised Learning)
非監督式學習(Unsupervised Learning)又稱為無監督學習,不同於監督式學習,它不需要標注資料,而是從無標注的數據中發掘隱藏的結構、規律或模式,進而分析輸入資料的類別(category)、轉換(transformation)或機率(probability)。
與監督式學習相同的是,非監督式學習中的所有可能輸入與輸出的集合分別稱為輸入空間(input space)與輸出空間(output space)。每一個輸出都是對輸入數據的分析結果,可以是類別、轉換或機率。
在建立非監督式學習模型時,所有可能的模型的集合形成假設空間(hypothesis space),目標是從假設空間中選擇在給定評價標準下的最佳模型。
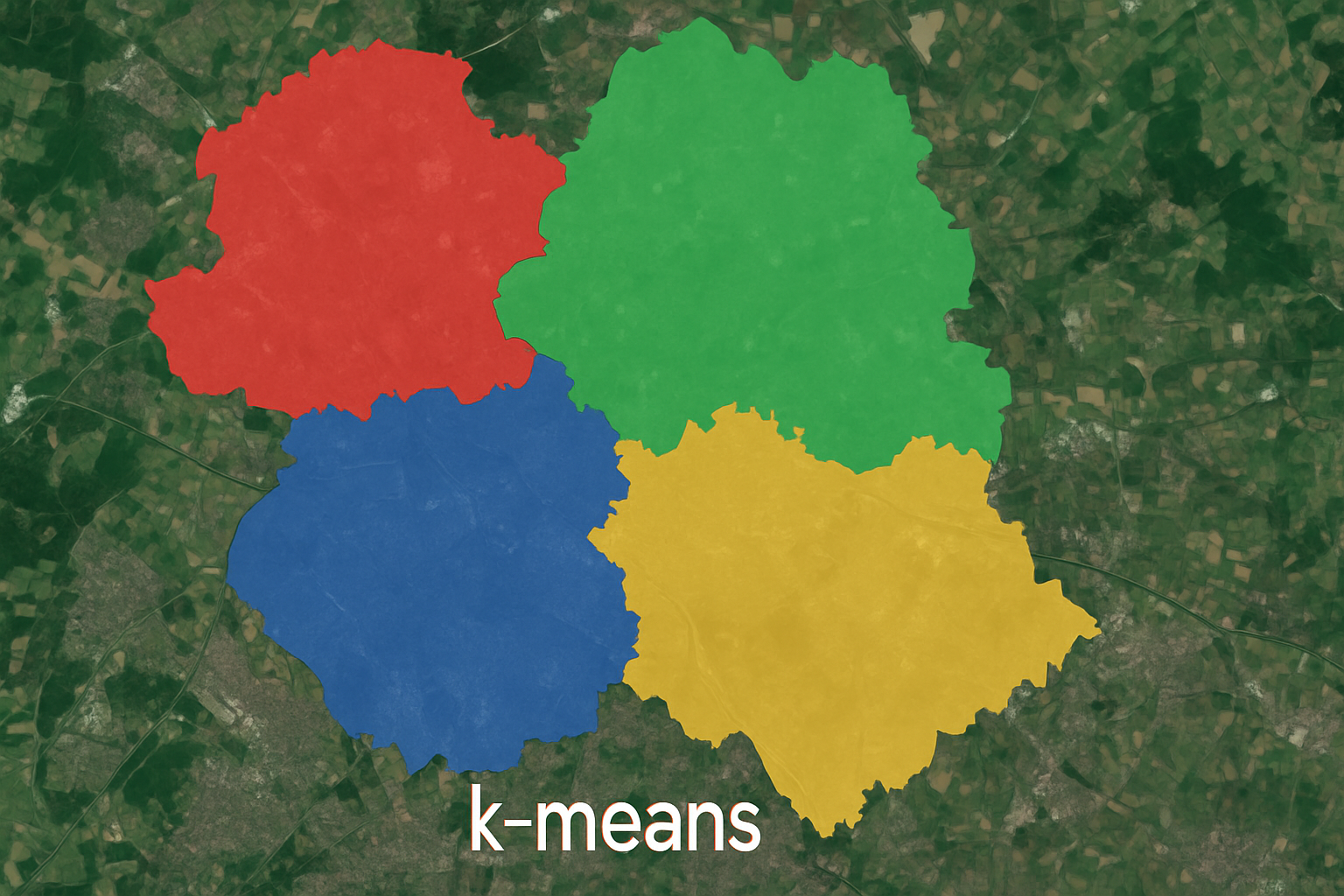
常見的非監督式學習方法有聚類(clustering)與降維(dimensionality reduction)。聚類是一種將相似的數據點歸為同一組的技術,例如 k-平均演算法(k-means clustering)、層次聚類(hierarchical clustering)和 DBSCAN。降維則用於在保留關鍵資訊的同時減少數據維度,例如主成分分析(PCA)與 t-SNE(t-Distributed Stochastic Neighbor Embedding)。
流程
$$ [輸入數據(無標籤)] \rightarrow [模型訓練] \rightarrow [找出規律] \rightarrow [輸出結果(如聚類或降維)] $$
應用
非監督式學習常用於資料探索,例如何時用聚類方法對客戶進行分群,或者在大數據中找到潛在的結構模式。
優缺點
優點:
- 不需要標注資料,對資料的要求較低。
缺點:
- 模型的結果較為模糊,需要更多的後處理來解釋結果。
強化學習(Reinforcement Learning)
強化學習是一種基於回饋的學習方法,模型會在一個環境中與之互動,並通過獲得的回饋來調整自己的行為,藉由不斷地試錯(trial and error)學習最佳策略,以最大化長期累積獎勵。這些回饋可以是正向的(獎勵,Reward),例如達成目標時獲得的分數;或負向的(懲罰,Penalty),例如因錯誤決策而產生的損失。
與監督式學習不同,強化學習的輸入與輸出不需要標籤,也無需明確指明何種行為是最優解。強化學習是在於尋找探索(對未知領域的)和利用(對已有知識的)的平衡,以持續提升決策品質。而這也是除了監督式學習和非監督式學習之外的第三種基本的機器學習方法。
流程
$$ [環境互動] \rightarrow [選擇動作] \rightarrow [獲取回饋] \rightarrow [試錯調整策略] \rightarrow [更新策略] \rightarrow [選擇下一動作] \rightarrow [重複學習] $$
應用
強化學習被廣泛應用於自動駕駛、機器人控制及遊戲領域。著名的例子包括 AlphaGo 和自動駕駛車輛的導航系統。
優缺點
優點:
- 能夠解決複雜的決策問題,並且具有學習與自我調整的能力。
缺點:
- 需要大量的計算資源,訓練時間長,且回饋信息的獲得有時較為困難。
半監督學習(Semi-Supervised Learning)
半監督學習介於監督式學習與非監督式學習之間,這種方法使用大量未標注的資料和少量標注的資料來進行學習,因為標注資料需消耗大量人工,耗時耗力;而未標注的資料較好取得,不需太多成本。半監督學習透過使用未標注資料中的資訊,輔助標注資料進行監督式學習,從而能夠以較低的成本達到較好的效果。因此,半監督學習也更接近監督式學習。
流程
$$ [標注 + 未標注數據] \rightarrow [模型初步學習] \rightarrow [預測未標注數據標籤] \rightarrow [擴展標注數據集] \rightarrow [重新訓練] \rightarrow [最終模型] $$
應用
半監督學習常用於標注困難或高成本的問題領域,如圖片辨識等標注的工作量巨大,這時半監督學習可有效提高模型性能。
優缺點
優點:
- 能夠減少標注資料的需求,降低標注成本。
缺點:
- 在實現過程中,如何選擇有效的未標注資料來進行學習是一大挑戰。
主動學習(Active Learning)
主動學習是一種特殊的半監督學習方法,在這種方法中,模型會主動選擇最具學習價值的未標注資料,請求人工標注,並將其納入學習過程,隨後利用標注資料學習並進行預測。通過這種方式,模型能夠以使用最少的標注資料來提高性能。
傳統的監督式學習通常隨機選取標注資料來訓練模型,這種方式可視為被動學習(Passive Learning);而主動學習則旨在識別對模型最有幫助的資料,優先進行標注,使模型能夠在最少的標注成本下獲得最佳學習效果。因此,與半監督學習類似,主動學習也更趨近於監督式學習。
流程
$$ [未標注數據] \rightarrow [模型選擇有價值樣本] \rightarrow [人工標注] \rightarrow [訓練模型] \rightarrow [更新模型] \rightarrow [迭代學習] $$
應用
主動學習在需要大量標注資料但無法輕易標注所有資料的情境中尤為重要。例如,在醫療影像分析中,使用主動學習能夠將標注精力集中於最具挑戰性的圖像上。
優缺點
優點:
- 提高標注效率,減少標注成本。
缺點:
- 需要模型能夠合理選擇最有價值的樣本,這對算法的設計提出挑戰。
結語
機器學習的發展與應用正持續改變各行各業,從監督式學習到其他機器學習方法,每種方法都有其特定的應用場景與優缺點。理解不同類型的機器學習方法,能幫助我們在實際問題中選擇最合適的技術解決方案。隨著技術的不斷進步,未來我們將看到更多融合不同方法的混合學習模式,並且能夠在更複雜的問題中發揮更大作用。
參考資料
李航(2022)。機器學習聖經:最完整的統計學習方法(初版)。深智數位股份有限公司。
歐幾里得空間(2025年2月20日)。維基百科,自由的百科全書。2025年4月3日參考自 https://zh.wikipedia.org/zh-tw/欧几里得空间
強化學習(2025年3月15日)。維基百科,自由的百科全書。2025年4月3日參考自 https://zh.wikipedia.org/zh-tw/强化学习