主成分分析(PCA)
是常見的降維(dimension reduction)方法,是將原先線性相依(linearly dependent)的資料集經由正交轉換(orthogonal transformation)後變成若干個線性獨立(linearly independent)的新變數表示的資料,使資料集經投影到新變數上損失的資訊量最小,並依新變數的變異數(variance)大小依次稱為第一主成分、第二主成分等。 PCA 常用於將高維度的資料映射到低維度空間,同時盡可能在降維過程中保留原始資料的重要特徵與訊息。")
封面圖片為 ChatGPT 生成的主成分分析圖片,提示詞為: “A detailed 2D scatter plot illustrating Principal Component Analysis (PCA). The data points are grouped into multiple clusters with different colors, representing various categories. The X and Y axes are labeled ‘PC1’ and ‘PC2’, with grid lines for reference. A semi-transparent convex hull encases each cluster to emphasize grouping. The background is clean white with subtle shadows. The title ‘PCA Visualization’ is prominently displayed at the top.” 。
前言
主成分分析(Principal Component Analysis, PCA)是常見的降維(dimension reduction)方法,是將原先線性相依(linearly dependent)的資料集經由正交轉換(orthogonal transformation)後變成若干個線性獨立(linearly independent)的新變數表示的資料,使資料集經投影到新變數上損失的資訊量最小,並依新變數的變異數(variance)大小依次稱為第一主成分、第二主成分等。 PCA 常用於將高維度的資料映射到低維度空間,同時盡可能在降維過程中保留原始資料的重要特徵與訊息。
PCA 原理:最大可分性和最近重構性
PCA 透過最大可分性和最近重構性兩種思路將資料集優化。其中,最大可分性指的是樣本投影到低維空間時,每一個投影點間的距離都能盡量分開;而最近重構性則是指每一個樣本點到其投影點的距離平方和要足夠小,就如同迴歸(regression)中的最小平方法(least squares method)。
假設存在以下資料點: $$ \mathbf{X} = (X_1, X_2, \cdots, X_p)^\top, $$ 其中, $X_j = (x_{1j}, x_{2j}, \cdots, x_{nj})$ , $i = 1, \cdots, n$ , $j = 1, \cdots, p$ , $\mathbf{X} \in \mathbb{R}^{n \times p}$ 。

最大可分性
從範例一的資料點,我們可以繪製 M 、 N 線段如下。


從以上資料點我們可以發現,資料點投影到 M 線段較投影到 N 線段分散,可以保留較多的資訊。若以統計角度說明,則可表達:各資料點在變數 M 上的變異數和較在變數 N 上的變異數和大。因此,我們會偏向選擇變異數和較大的變數作為第一主成分(PC1),例如範例一中的變數 M ,次之為第二主成分(PC2),並以此類推。
最近重構性
從最大可分性中繪製的 M 線段與 N 線段,我們也可以觀察到 M 線段中資料點與其投影點的距離平方和相較於 N 線段小。而我們通常會優先選擇投影距離平方和較小的變數作為第一主成分,也就是投影誤差(原始點與投影點的歐幾里得距離平方和)最小的變數為第一主成分,並以此類推。
由畢氏定理,我們知道在資料中心點固定的情況下,資料點與中心點的距離相同,則對於任意線段,投影距離愈長則投影點到資料中心點的距離愈短,投影距離愈短則投影點到資料中心點的距離愈長,即 PCA 選擇的方向同時最大化變異數並最小化投影誤差,因此最大可分性與最近重構性本質上是等價的。
中心化
中心化讓資料改以坐標原點為中心,且不影響資料的分布情況。為方便正交轉換以及簡化矩陣運算過程,我們會在計算 PCA 的過程中進行中心化。
簡單來說,假設資料點同範例一一樣,我們可以選取各資料點平均並算出原資料中心點。
假設 $\overline{x}_j$ 為 $X_j$ 的平均值,則
$$ \overline{x}_j = \frac{1}{n} \sum_{i = 1}^n x_{ij}, \quad j = 1, \cdots, p, $$


並原矩陣減去其平均值即可獲得中心化後的新矩陣(將資料中心點平移至原點處)。
$$ \mathbf{X}_c = \mathbf{X} - \overline{\mathbf{X}} = \begin{pmatrix} x_{11} & x_{12} & \cdots & x_{1p} \\ x_{21} & x_{22} & \cdots & x_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{np} \end{pmatrix} - \begin{pmatrix} \overline{x}_1 & \overline{x}_2 & \cdots & \overline{x}_p \\ \overline{x}_1 & \overline{x}_2 & \cdots & \overline{x}_p \\ \vdots & \vdots & \ddots & \vdots \\ \overline{x}_1 & \overline{x}_2 & \cdots & \overline{x}_p \end{pmatrix} $$

標準化
標準化(standardization)是為了消除不同資料間因尺度等因素而對結果產生的影響,並使各資料可在相同標準下(平均值為 0 ,標準差為 1 )被檢視、提供參考價值。標準化的流程與中心化類似,但增加了除以標準差這一步。與中心化相同的是,標準化後的資料集仍擁有與原資料即相同的排序、分布情況,一般在進行資料預處理時都會先進行中心化再考慮是否需要進行標準化。
假設現在要分析一筆資料,其中我們收集了以下資訊:
| 1 | 2 | 3 | 4 | ⋯ | |
|---|---|---|---|---|---|
| 身高(公分) | 180 | 160 | 175 | 170 | ⋯ |
| 年齡(歲) | 20 | 22 | 26 | 18 | ⋯ |
已知欲分析的資料與身高較無關係,與年齡較相關。但因為身高較年齡差了近 10 倍,故身高的變異數較大,這可能導致 PCA 在選擇主成分時更偏向選擇身高這個變數,而非年齡,即使身高所攜帶的資訊並沒有比年齡多。
我們也可以對範例一中的資料點進行標準化。假設 $\sigma^2_j$ 為 $X_j$ 的變異數,由變異數的定義我們可寫下:
$$ \sigma^2_j = \frac{1}{n} \sum_{i = 1}^n (x_{ij} - \overline{x}_j)^2, \quad j = 1, \cdots, p, $$
因此,將資料集標準化的結果為
$$ \mathbf{Z} = \frac{\mathbf{X}_c}{\mathbf{\sigma}} = \frac{\mathbf{X}-\overline{\mathbf{X}}}{\mathbf{\sigma}}, $$
其中
$$ \mathbf{\sigma} = \begin{pmatrix} \sigma_1 & \sigma_1 & \cdots & \sigma_1 \\ \sigma_2 & \sigma_2 & \cdots & \sigma_2 \\ \vdots & \vdots & \ddots & \vdots \\ \sigma_p & \sigma_p & \cdots & \sigma_p \end{pmatrix}. $$
資料點投影
經過中心化、標準化等資料預處理方法後,接下來要將資料點投影到新變數上。
假設現有資料向量 $x_i$ ,現在我們想將 $x_i$ 投影到 $v$ 上,稱為 $w$ 。則由投影夾角 $\theta$ ,我們可以知道 $w$ 的長度為 $\|x_i\| \|v\| \cos(\theta)$ ,其中 $\|x_i\|$ 表示 $x_i$ 的長度。若 $v$ 為單位向量(unit vector),則 $w$ 的長度可改寫為 $\|x_i\| \cos(\theta)$ 。

以上為單個資料點的投影公式。
現在考慮資料集中多資料點的投影。假設使用範例一中的資料點 $\mathbf{X} = (X_1, X_2, \cdots, X_p)^\top$ ,其中 $X_j = (x_{1j}, x_{2j}, \cdots, x_{nj})$ 。令 $\mathbf{\delta} = (\delta_1, \delta_2, \cdots, \delta_p)^\top$ 是 $\mathbf{X}$ 的投影方向(主成分向量),則所有資料點的投影可寫成
$$ \mathbf{\mathcal{P}} = \mathbf{\delta}^\top \mathbf{X} = (\delta_1, \delta_2, \cdots, \delta_p) \begin{pmatrix} X_1 \\ X_2 \\ \vdots \\ X_p \end{pmatrix} = \sum_{j=1}^p \delta_j X_j, $$
$\mathbf{\mathcal{P}} = (\mathcal{P}_1, \mathcal{P}_2, \cdots, \mathcal{P}_p)^\top$ 。其中 ${\delta}$ 要符合 $\sum_{j=1}^p \delta_j^2 = 1$ 用以保證投影到的向量為單位向量。
變異數計算
那我們要怎麼找到適合的投影方向 $\mathcal{P}_i$ ,使得我們在該投影向量上擁有最大可分性呢?已知以下條件
$$ \max_{\{\delta:\|\delta\| = 1\}} Var(\mathbf{\mathcal{P}}) = \max_{\{\delta:\|\delta\| = 1\}} Var(\mathbf{\delta}^\top \mathbf{X}) = \max_{\{\delta:\|\delta\| = 1\}} \mathbf{\delta}^\top Var(\mathbf{X}) \mathbf{\delta}, $$
為了找到最大的變異數,我們必須先找到適合的 $\mathbf{\delta}$ 。在此之前,我們需要先知道以下定理:
如果 $\mathcal{A}$ 是對稱矩陣(symmetric matrix),則
$$ \max_x x^\top \mathcal{A} x = \lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_p = \min_x x^\top \mathcal{A} x, $$
其中, $\lambda_1, \lambda_2, \cdots, \lambda_p$ 是 $\mathcal{A}$ 的特徵值(eigenvalue)。
根據以上定理,我們可以知道投影方向 $\mathbf{\delta}$ 可由共變異矩陣(covariance matrix) $\Sigma = Var(\mathbf{X}) \in \mathbb{R}^{p \times p}$ 中最大的特徵值 $\lambda_1$ 所對應的特徵向量(eigenvector) $\gamma_1$ 給定。
主成分分析
第一主成分
回到一開始的例子,假設範例一中的資料點 $\mathbf{X}$,從變異數計算中所提到的定理,我們可以知道第一主成分(first principal component, PC1)為
$$ Y_1 = \gamma_1^\top \mathbf{X}, $$
且 $Y_1 \in \mathbb{R}^p$ 擁有投影後最大的變異數 $$ \argmax_{\{\gamma_1:\|\gamma_1\| = 1\}} \mathbf{\gamma_1}^\top Var(\mathbf{X}) \mathbf{\gamma_1}, $$
即 $\gamma_1$ 滿足
$$ \Sigma \gamma_1 = \lambda_1 \gamma_1. $$
由資料集 $\mathbf{X}$ ,我們可知 $E(\mathbf{X}) = \overline{\mathbf{X}}$ ,且 $Var(\mathbf{X}) = \Sigma$ 。將共變異矩陣 $\Sigma$ 對角化(diagonalization)可得
$$ \Sigma = \Gamma \Lambda \Gamma^\top, $$
因此,我們也可得 PC1 為
$$ Y_1 = \Gamma^\top_1 (\mathbf{X}-\overline{\mathbf{X}}) = \Gamma^\top_1 \mathbf{X}_{c} \in \mathbb{R}^n. $$
第二主成分
現在我們已經得出 PC1 $Y_1$ 與其投影向量 $\mathcal{P}_1$ 。類似地,我們可以用相同的方法找出第二主成分(second principal component, PC2)。需要注意的是,PC2 的投影向量需與 PC1 垂直,換句話說
$$ \mathcal{P}_2^\top \mathcal{P}_1 = 0, $$
而 PC2 的變異數為
$$ \argmax_{\left\{\gamma_2:\|\gamma_2\| = 1, \gamma_2^\top \gamma_1 = 0 \right\}} \mathbf{\gamma_2}^\top Var(\mathbf{X}) \mathbf{\gamma_2}. $$
若 $\gamma_2$ 符合以上條件,即可稱為 PC2
$$ Y_2 = \Gamma^\top_2 (\mathbf{X}-\overline{\mathbf{X}}) = \Gamma^\top_2 \mathbf{X}_{c} \in \mathbb{R}^n. $$
其他主成分
總結以上,對於第 $q$ 主成分,我們會有
$$ Y_q = \Gamma^\top_q (\mathbf{X}-\overline{\mathbf{X}}) = \Gamma^\top_q \mathbf{X}_{c} \in \mathbb{R}^n, $$
且其投影向量 $\mathcal{P}_q$ 必與 $\mathcal{P}_{q-1}$ 垂直( $\mathcal{P}_q^\top \mathcal{P}_{q-1} = 0$ ),主成分總數量不超過資料集的特徵數量 $p$ 維度。
對於主成分 $\mathbf{Y} = \Gamma^\top \mathbf{X}_{c}$,存在以下特性:
對於給定資料集 $\mathbf{X} \sim (\overline{\mathbf{X}}, \Sigma)$ ,令 $\mathbf{Y} = \Gamma^\top (\mathbf{X} - \overline{\mathbf{X}})$ 為主成分轉換(PC transformation),則
$$ E(Y_j) = 0, \quad j = 1, \cdots, p \\ ~ \\ Var(Y_j) = \lambda_j, \quad j = 1, \cdots, p \\ ~ \\ Cov(Y_i \ne Y_j) = 0, \quad i \ne j \\ ~ \\ Var(Y_1) \ge Var(Y_2) \ge \cdots \ge Var(Y_p) \ge 0 \\ ~ \\ \sum^p_{j=1} Var(Y_j) = tr(\Sigma) \\ ~ \\ \prod^p_{j=1} Var(Y_j) = |\Sigma|. $$
Python 範例
資料集簡介
本次使用的資料集為 Boston housing data ,這是關於美國麻薩諸塞州首府——波士頓 1978 年的房價資料,該資料集包含波士頓都市區每個人口普查區的 506 個觀察值。
變數說明
由 Applied Multivariate Statistical Analysis 這本書,我們可以知道此資料集共 506 筆資料, 14 個變數。每個變數說明如下:
| 變數 | 說明 |
|---|---|
| $X_{1}$ | 人均犯罪率 |
| $X_{2}$ | 用於大面積地塊的住宅區土地比例 |
| $X_{3}$ | 非零售業務區域的比例 |
| $X_{4}$ | 查爾斯河(如果區域邊界為河流,則為 1,否則為 0) |
| $X_{5}$ | 一氧化氮濃度 |
| $X_{6}$ | 每個住宅單位的平均房間數 |
| $X_{7}$ | 1940 年前建造的擁有者自住單位的比例 |
| $X_{8}$ | 到五個波士頓就業中心的加權距離 |
| $X_{9}$ | 到徑向公路的可達性指數 |
| $X_{10}$ | 每 $10,000 的全額房產稅率 |
| $X_{11}$ | 師生比 |
| $X_{12}$ | 1000 × B × (1 - 0.63 / 2) < 0.63,其中 B 為非裔美國人比例 |
| $X_{13}$ | 低收入人口比例 |
| $X_{14}$ | 自有住宅的中位數價值(以 $1,000 為單位) |
資料集
以下使用 Python 作為分析 PCA 的語言。
| |
資料集部分資訊如下。
| |
同時使用以下程式碼檢視資料及是否有缺值。
| |
| |
從以上結果可知,此資料集不存在缺值。
定義變數與標準化
接下來,我們定義特徵變數 x 與目標變數 y 。藉由定義特徵變數和目標變數,後續完成 PCA 後可將結果(PC)再使用其它模型進行分析,如隨機森林等。如果僅需要進行 PCA ,可以只將全部變數都定義為特徵變數。
| |
PCA
接下來,我們將進行主成分分析。在這邊,我們使用 scikit-learn 的 PCA() 函數,而 PCA() 函數也可以使用 n_components 參數決定要保留多少變異數。此處不填寫n_components 參數,表示保留全部參數(最大變異數)。
| |
| |
此處我們也能直觀的看到主成分總數量不超過資料集的特徵數量。
接下來,我們輸出 PCA 的成分矩陣與變異量,並輸出成 data frame 方便查看。
| |
| |
從以上結果我們可以觀察到, PC1 的解釋變異量為 PC2 的 4 倍,可見 PC1 在解釋資料集變異性方面的主導地位。進一步觀察累計解釋變異量(Cumulative Explained Variance),我們發現隨著主成分的增加,解釋的變異量累積速度變慢。這讓我們能夠有依據地決定在降維後保留多少主成分,達到讓資料集有效解釋,但又能避免過多的維度帶來的冗餘資訊和計算負擔。因此,根據這些結果,我們可以選擇保留前幾個主要的主成分來有效地解釋資料,而不必保留所有的主成分。
以下繪製剩餘累積變異量圖,讓我們能更直觀的觀察剩餘累積變異量,並決定要保留的主成分數量。
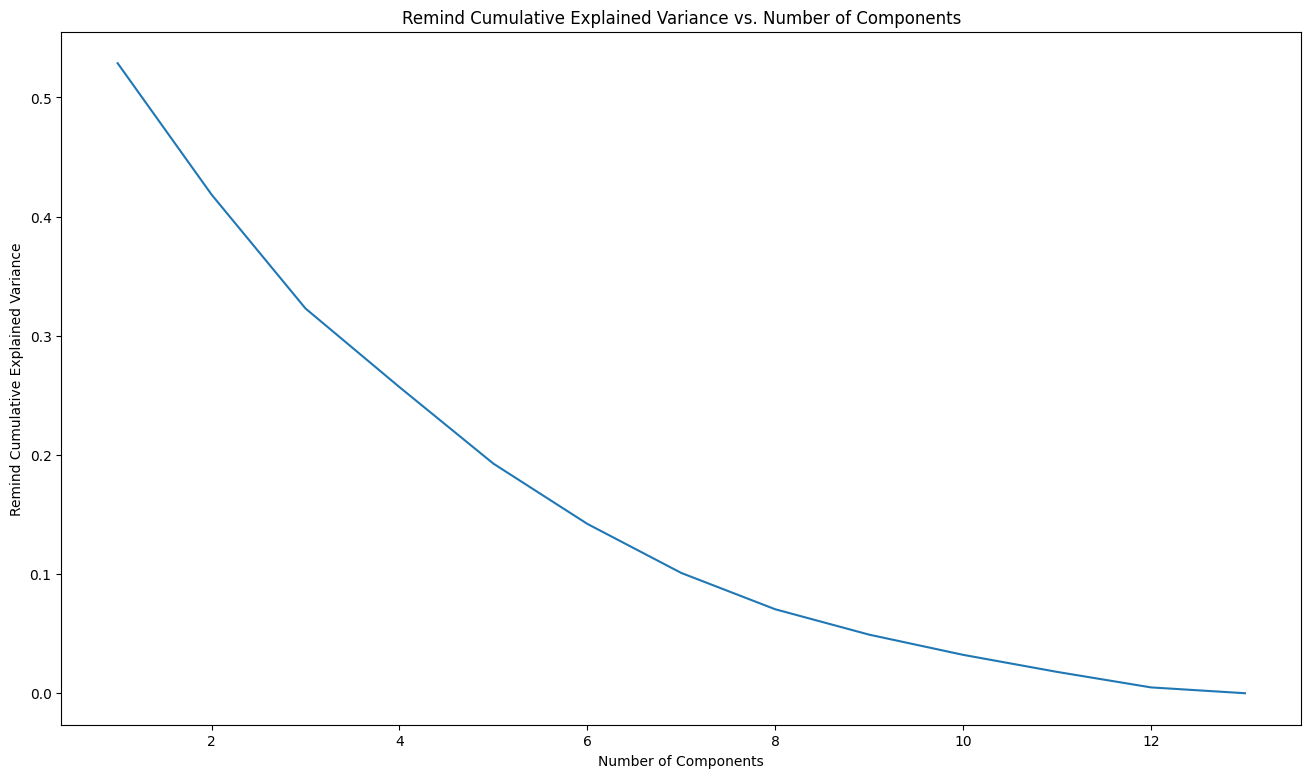
使用以下程式碼能找出所有經主成分轉換(PC transformation)後的點
| |
| |
PC1 小提琴圖
我們可以使用小提琴圖查看 PC1 資料的分布情況。
| |
若無法查看互動式 PC1 小提琴圖,或是需要全螢幕檢視,請點此處前往。
PC1 與 PC2 散佈圖
我們可以使用散佈圖查看 PC1 與 PC2 資料的分布情況。
| |
若無法查看互動式 PC1 與 PC2 散佈圖,或是需要全螢幕檢視,請點此處前往。
結語
PCA 是一個實用的降維方法,能將資料集從複雜的 $p$ 維度在盡可能保留資訊的情況映射到 $q$ 維度空間。使用 PCA 有助於減少資料的維度,從而降低計算和儲存成本,並提高模型的效率與準確性。通過去除不必要的噪音和特徵間的相關性,PCA 能夠改善機器學習模型的泛化能力,並且使得資料更具可解釋性。
運行環境
- 作業系統:Windows 11 24H2
- 程式語言:Python 3.12.9
延伸學習
- 本文使用的 ipynb 檔案。
參見
參考資料
Wolfgang karl härdle 和 léopold simar(2015年)。Applied Multivariate Statistical Analysis(第四版)。Springer。https://link.springer.com/book/10.1007/978-3-662-45171-7
动画讲编程。(2022年8月2日)。机器学习,什么是PCA降维?一个动画告诉你答案 [影片]。YouTube。2025年3月25日參考自https://youtu.be/FI0H_HStNJU
Tommy Huang。(2018年4月20日)。機器/統計學習:主成分分析(Principal Component Analysis, PCA)。2025年3月25日參考自https://chih-sheng-huang821.medium.com/機器-統計學習-主成分分析-principle-component-analysis-pca-58229cd26e71
李錦州。(2024年1月27日)。主成分分析 (Principal Component Analysis, PCA)。2025年3月25日參考自https://jinzhou.netlify.app/posts/principal-component-analysis/
Quantnet。(2025年1月27日)。 MVA。Github。https://github.com/QuantLet/MVA
Violin Plots in Python。(無日期)。Plotly|Graphing Libraries。2025年4月1日參考自https://plotly.com/python/violin/
李航(2022)。機器學習聖經:最完整的統計學習方法(初版)。深智數位股份有限公司。